前些日志, 有 G友 为 untp 添加了这么一条 issue:
还是比较有意思的, 早就知道 TexturePacker 提供了加密资源的功能, 但还没有实际使用过, 何不借此机会研究一下 ?
一. 初探 Content protection
我们很容易在 TexturePacker 中找到这个功能:
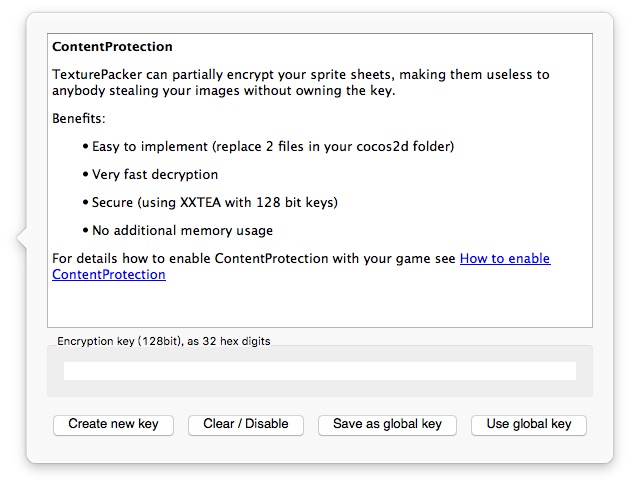
更详细的说明在这里, 里面提供了 Cocos2D 版本的解密文件 ZipUtils.m 和使用说明. 想比与这份 Objective-C 版, Cocos2d-x 的 C++ 版本才是我们今天的主角.
通过阅读代码, 我们可以得知 ZipUtils::decodeEncodedPvr 内的逻辑大约分为两部分:
- 通过原始密钥成成加密密钥
- 解密图片的数据块
这里面比较复杂的部分是生成密钥的部分. 将 4 个 uint 类型的原始密钥数组经过一个复杂的算法生成了 1024 个 unit 类型的数字.
解密的逻辑就很简单了, 只是与密钥简单的异或而已. 为了提高加解密速度, 只有前 512 个单元 是逐个加密的, 后面的每 64 个单元加密一个单元.
二. 解密 Content protection
知道了原理, 让我们来为 untp 实现一下解密的功能吧. 虽说有了 c++ 版的实现, 但翻译改为 Python 版时也遇到了不少问题, 所幸最后还是搞定了, 代码在这里, 下面我们来说说过程中遇到的问题.
1. ++
在解密的过程中加密密钥的索引 b 总是以 b++ 的形式进行递增, 而 Python 是不支持 ++/-- 操作符的, 我们可简单的换为 b += 1 这样的语句替代, 但是要记住先取值再递增.
另外一处是 for 循环的控制变量 i 也是以 ++i 的形式进行递增的, 我们可以将将循环换成 range 函数替代:
1 | i = 0 |
但是 C++ 版本又对 i 进行了复用, 这会导致我们的 i 在循环结束后比 c++ 版本少 1, 需要再递增一次才能一致.
2. unsigned int 溢出问题
我们的每一个密钥和原始数据的每一块都被当做一个 unsigned int 进行处理, 这过程中会有相加的逻辑, 可能会导致结果大于 uint 的最大值 2 ^ 32 - 1. C++ 操作会对超出的部分自动丢弃, Python 却会对数据类型进行升级, 编程 long 类型, 这就导致了结果的不一致, 我们可以通过与最大值进行 & 操作达到同样的目的:
1 | def long_to_uint(value): |
3. byte 和 number 的互相转换
C++ 版本中只需要将 unsinged char* 变为 unsinged int* 就能实现每 4 字节变成一个 uint, Python 中则需要借助 strcut 库.
1 | # byte to number |
4. ccz 文件头
PVR 格式本身不是压缩格式纹理, 如果不进行压缩的话会很大, TexturePacker 针对 PVR 可以输出两种压缩格式: ccz 和 gz, 但只有 ccz 支持加密. 按照 C++ 中的定义, ccz 文件头如下:
1 | struct CCZHeader { |
这里面比较有用的是 sig, 未加密的格式是 CCZ!, 加密的格式是 CCZp, 我们可以通过它的取值提前判断是否进行了加密. Python 读取 CCZHeader 可以用如下代码:
1 | def _pvr_head(_data): |
值得注意的是, 最然 len 属于文件头, 但也被加密了.
三. 小技巧
其实这个功能从很早就开始做了, 只是一开始始终不得要领, 反复调试, 使用 XCode 跑起来 C++ 版实现对比内存, 直到我掌握了一些小技巧.
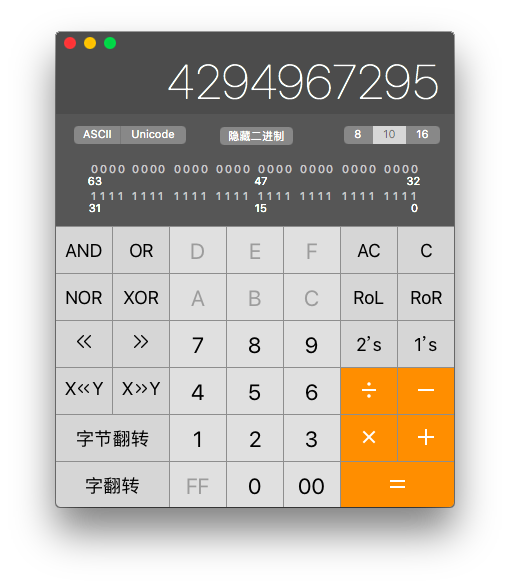
1. 计算器观察二进制排布
使用 Mac 自带的计算器开始程序员模式后可以很方便的观察一个数字的二进制排布情况, 点击每一位还可以进行修改, 特别方便:
2. 参照文件
有一个问题, 如何得知我们解密的后文件是否正确, 差在哪里呢 ? 一开始我也是靠猜测, 后来去对比内存, 但是都很麻烦, 最终我想到了一个妙招:
既然 C++ 版都已经解密成功了, 那我直接把这个数据保存下来, 不就知道了目标二进制数据了嘛 !
1 | FILE *fp = fopen((cocos2d::FileUtils::getInstance()->getWritablePath() + "temp.pvr.ccz").c_str(), "wb"); |
3. 对比二进制数据
我使用的是 Sublime Text, 切成了两个窗口:
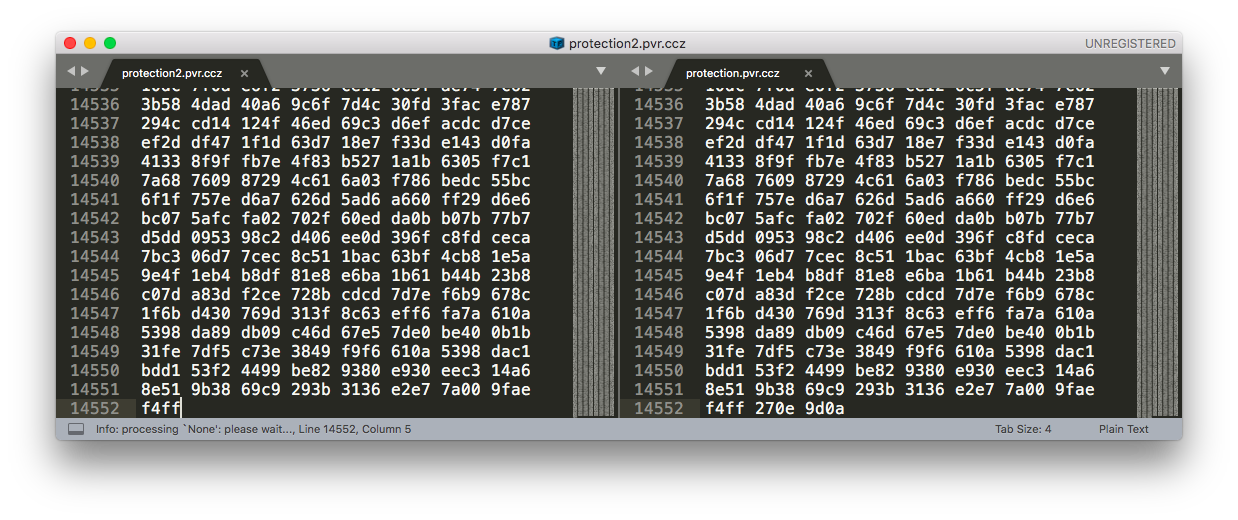
左右扫一下便知道哪个数据不对, 我最后一步少了文件尾就是通过这个看出来的.
四. 后记
总的来说, 这次尝试收获颇丰, 后面自己打算做的一个小工具恰好能用上这次学习到的内容, 感觉自己棒棒哒.
当然, untp 对于加密 PVR 的支持还可以做到更好, 现在只支持单密钥, 其实是可以做到多密钥多次尝试找到一个可用, 这次因为拖的比较久了想赶紧搞定就没有做, 下一版补上.